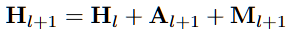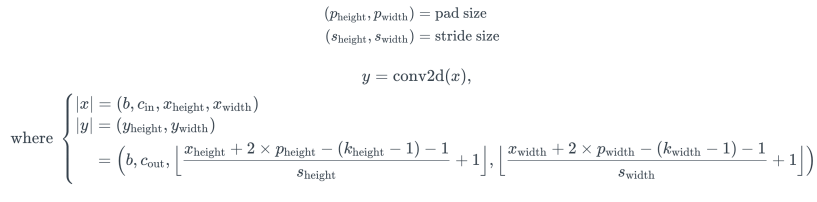0. LLM workflow1)입력 인베딩 -> 2)트랜스포머 블록(멀티 헤드 어텐션, 피드포워드 네트워크, 잔차 연결 및 정규화) -> 3)출력 레이어 4) 출력 디코딩1. 정의Residual Connection은 신경망에서 발생하는 기울기 소실(vanishing gradient) 문제를 해결하기 위해 도입되었다.신경망의 특정 층에서 입력값을 출력값에 더해주는 방식인데, 어떤 변환을 수행한 F(X)에원래 입력값인 X를 더해 최종 출력을 만든다. Y = F(X) + X ## 트랜스포머 블록 구조 상 멀티 헤드 어텐션(출력)과 피드 포워드 네트워크(출력과 입력)에 적용import torchimport torch.nn as nnclass FeedForwardNetwork(nn.Module): def _..