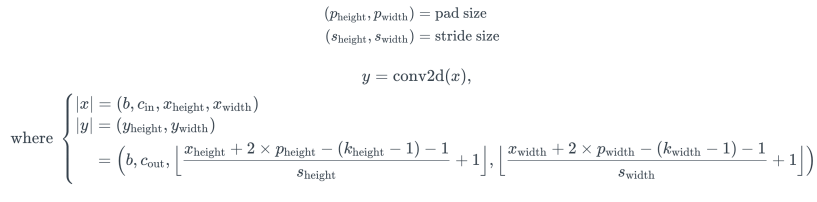1. Tmux란? 터미널 멀티플렉서로, 하나의 터미널 세션에서 여러 개의 창을 관리하고, 세션을 분리하거나 재접속하는 등 유용한 기능을 제공하는 tool을 의미한다-> 즉, 우리가 모델을 돌릴 때 사용하고 있는 컴퓨터에서 여러 작업 터미널 창을 만들어 주며, tmux에 넣은 작업은 실제 작업 종료 전 까진 중단되지 않는다(작동중인 컴퓨터 종료해도 무관) 2. Tmux 구성요소: 세션(여러 터미널 창을 그룹화), 윈도우(작업 공간), Pane(독립적인 터미널 창) 3. Tmux 설치conda install -c conda-forge tmux # conda# 우분투 기반 도커 컨테이너apt-get updateapt-get install -y tmux# macOSbrew install tmux 4. 명령어# ..