Summary
해당 논문은 할루시네이션 탐지 방법 중 모델 튜닝을 하지 않고 single response를 활용한 방법이다.
출력 토큰 생성 시 attention map과 hidden_state, output prediction probabilities 값을 사용하여
불확실한 토큰(할루시네이션한 답변) 탐지에 집중하였다.
(NuerIPS 2024, Sriramanan et al.)
Contributions
1) Model inner states를 활용한 저비용 할루시네이션 탐지 방법 제안
2) 기존에 연구되어 오던 반복 샘플링 기반 할루시네이션 측정방법과 외부지식 활용방법 보다 우수함을 증명
Introduction
저자는 LLM 할루시네이션 탐지 방법 중 uncertainty estimation 방법론에 집중하였다.
기존에 연구되어 오던 방법론들은 1) prompt Input에 대한 답변의 일관성여부(일부 답변 샘플에선 비정상 답변) 2) 외부지식(Retrieval-Augmentation-Generation)을 활용한 방법론은 Time cost가 많이 발생함을 지적하였다.
*SelfcheckGPT: Blackbox model의 response를 샘플링하여 BERTSCORE, NGRAM 등으로 평가 *INSIDE: response를 샘플링하면서 model 내부의 Eigenscore의 변화 여부(이상한 답변은 일관되지 않음)
Objective
현실세계 문제 해결을 위해 프롬포트를 포함한 LLM의 쿼리 x에 대한 답변 y의 할루시네이션 여부 파악
환각 탐지방법
1. 외부참조가 없는 경우: LLM에게 추가적인 Context 정보를 제공할 수 없는 경우
1a) 단일 응답: FAVA Human-Annotated 데이터셋 활용, 모델의 하나의 답변만을 평가 1b) 다중 응답: SelfCheckGPT & INSIDE 방법론 이용, LLM의 여러 응답을 활용하여 답변의 일관성여부 평가
2. 외부참조가 있는 경우: 외부 자료에서 검색된 다양한 데이터를 활용하여 모델의 응답을 평가할 수 있는 경우
2a) White-box based: 기존 LLM의 내부 활성화 값들을 활용 가능한 열린 모델에 적용
2b) Black-box based: 기존 LLM에 접근할 수 없어 Teacher-forcing을 open source llm에 적용
Hypothesis: LLM이 답변을 생성할 때 내부 표현 방식에 차이가 있을 것이라 가정(환각 정보와, 진실된 정보 생성 시)
Method
할루시네이션 점수
- Hidden representation = 직전 레이어값의 Hidden representation + Attention + MLP
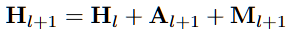
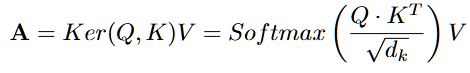
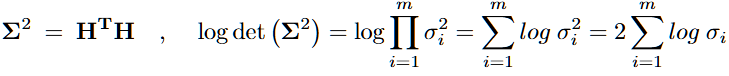
Hidden Score: 특이값 분포가 퍼질 경우 모델이 불확실(환각상태이다)하다는 것을 가정(특이값 평균값 사용)
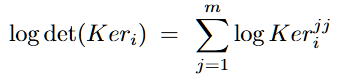
Attention Score:어텐션 패턴 값의 변화 여부를 분석하여 모델이 내부적으로 어떤 토큰에 집중하는지, 그림 (4)
- 특정 토큰이 주로 참조되는 게 아니라 여러 토큰을 고르게 참조(행렬이 분산될 때) 환각현상이 발생할 것이다.
출력 토큰의 불확실성 정량화
- Next token prediction 방식에서 Perplextiy와 Logit Entropy, Window Logit Entropy로 이를 확인
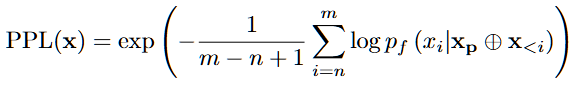
Perplextiy: 특정 문장을 얼마나 확신을 가지고 생성했는 지(낮을수록 자신감이 높음)
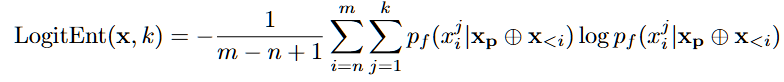
Logit Entropy: 개별 토큰 단위에서의 불확실성 분석(낮을수록 후보군에 대한 확신도가 강해서 환각가능 낮음)
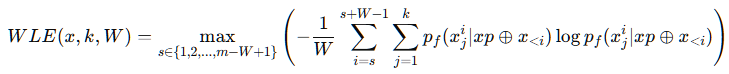
Window Logit Entropy: 환각이 문장 일부에서만 발생할 수 있다는 한계를 보완(평균은 부적절)
- 문장을 일정 길이의 윈도우로 나누어 분석(가장 불확실성이 높은 윈도우 값을 최종 점수로)
기존 연구들은 정답의 이진 분류(Yes or No)에 대한 할루시네이션만 탐지하려하였으며, 여러 유형의 할루시네이션에 대해서는 탐지하려하지 않았다(False positive가 발생할 수 있음) 따라서 주어진 프롬포트로 특정 input을 extraction하면서도 input에 대해 단계적 검증과 외부지식 증강 기법을 적용하였다.
Factual Checking: Non-fabrication hallucination Check
설계한 프롬포트에서 input의 Non-fabrication hallucination을 확인하고 다음 5단계 method로 input 전달
(a) Step-wise Reasoning and Quer
- original input query -> 작은 sub 쿼리로 분할 -> 개별 sub 쿼리에 대해 지식 검색(위키피디아 지식)
- original query에 대해 제공한 instruction으로 논리적인 검증을 할 수 있게 세분화 & 개별쿼리 사실확인
- ex) Luke Skywalker 캐릭터가 처음 등장한 1977 년 우주 테마 영화의 유명한 악보를 누가 작곡 했습니까?
- 서브쿼리는 더 세부적인 지식을 확인: 루크 스카이워커가 등장한 1977년 우주 테마 영화는 무엇입니까
- 쿼리에 대해 일반적인 평서문 형식의 General 쿼리와 주된 개체를 포함한 Specific 쿼리를 구성
(b) Knowledge Retrieval retrieves knowledge for each sub-query based on existing knowledge database
- 전달받은 서브 쿼리 질문을 위키피디아에 검색(Top-K로 연관된 지문 가져오기)
(c) Knowledge Optimization summarizes and refines the retrieved knowledge, and maps them to different forms, such as unstructured knowledge (object-replicate-object triplet)
- 다른 LLM으로 검색된 지식이 너무 길거나 비문이 많기 때문에 간결하게 만들어주는 방식
- Structured: 객체-술어-객체 형태로 변경, (“Star Wars", was, 1977 space-themed movie) and (Luke Skywalker, first appeared in, “Star Wars")
- Unstructured: ‘Star Wars,’ released in 1977, is the space-themed movie in which the character Luke Skywalker first appeared.'
(d) Judgment Based on Multi-form Knowledge assesses the answer for each sub-query based on multi-form knowledge
- 서브 쿼리로부터 지식을 가져오면 #Query와 #Knowledge를 LLM이 판단할 수 있게 전달(#Judgement)
- 하위 쿼리와 해당하는 지식을 평가하여 모순이 있는 지 확인(INCORRECT, CORRECT, INCONCLUSIVE)
(e) Aggregation combines insights of judgments based on different forms of knowledge and makes a further refined judgment
- 반복으로 수집한 판단결과를 집계(낮은 신뢰도로 형성된 답변의 편향을 줄이기 위해 더 높은 신뢰도의 대체 답안 채택)
- 100개의 검증 데이터셋에서 각 지식 형태에 따른 신뢰도 점수 분포(분위수) 수집 및 점수 기준 임계값 설정
Experiment & Results

- 엔트로피 기반 방법보다 SelfCheckGPT-Prompt방식이 더 좋은 성능 확보, 제안하는 방법 중 Attn score가 가장 좋음
- Layer20에서 사용 시 가장 높은 어텐션 스코어 확보

- 여러 응답을 사용하는 Selfcheckgpt보다 단일 응답을 사용하는 LLM check방식이 더 좋은 성능 확보

- White box setting에선 Hidden score, Black box setting에선 Attention score가 우수, 모델 크기와 성능 비례

- Ours 기법은 연산비용이 가장 저렴하고 효과적
- 환각이 합성으로 삽입된 데이터에서 탐지 성능 평가, 엔트로피 기반 불확실성 측정이 더 효과적일 수 있음을 확인
결론
모델 내부의 uncertainty estimation으로 할루시네이션을 추정하는 방법은 굉장히 효율적이다, 다만 할루시네이션의 정의에 따른 개별 데이터셋 구성과 벤치마크 사용으로 정밀한 실험세팅에 어려움에 처할 수 있다.